RL-survey
強化学習のサーベイ論文(2023)
DQN
Deep Q Network が 2015 に登場し,教師なし学習の一種である(深層)強化学習は一斉に研究される用になった.
RL(強化学習)
Agent が環境との相互作用の中で試行錯誤を繰り返し,報酬を最大化する中で最適な方策を学ぶアルゴリズム.
マルコフ性
マルコフ性は,環境の遷移が現在の状態と行動のみに依存する性質である.
\[P(s_{t+1} \mid s_t, a_t, s_{t-1}, a_{t-1}, \dots, s_0, a_0) = P(s_{t+1} \mid s_t, a_t)\]MDP(マルコフ決定過程)
行動を実行した後,エージェントは報酬 $r_{t+1}$ を受け取り,報酬関数 $R(s_t, a_t, s_{t+1})$ および遷移分布$P(s_{t+1}|s_t, a_t)$ に従って次の状態 $s_{t+1}$ に遷移する. その時に報酬を最大化するような方策を学習するのが MDP である.
flowchart LR
A[Env 1] -->|確率r| B[Env 2]
A -->|確率1-r| C[Env 3]
B -->|確率1-s| A
B -->|確率s| C[Env 3]
C -->|確率1-t| B
C -->|確率t| A
マルコフ決定過程
flowchart LR
A[エージェント] -->|環境| B[環境]
B -->|報酬| A
A -->|方策| C[方策]
C -->|行動| B
強化学習の概念図
- Agent は環境に対して行動を起こし,環境が次状態に移行することにより報酬を得る.
- この報酬から Agent は方策を更新する.
- この過程を繰り返し,報酬を最大化するような方策を学習する.
時刻$t$から相互作用終了までのリターンは,
\[G_t = \sum_{i=0}^{\infty} \gamma^i r_{t+i}\]ここで$\gamma \in [0, 1]$は割引率である.
この式により,直近の報酬を重視するのではなく,長期的な報酬を最大化するような方策を学習する. このリターンを最大化することにより,エージェントは環境に対して最適な方策を学習する.
DRL(深層強化学習)
上記の強化学習の方策を NN(ニューラルネットワーク)を用いて表現する方法. NN を用いることにより例えば非線形な,より複雑な環境に対する報酬を表現することが可能である.
- 高次元かつ大規模な状態空間を扱う.
- ラベル付きデータセットが必要でない.
- オフライン学習が可能になる(すでに集めたデータだけで環境を使わず学習できる.)
ロボットや医療現場では何度も環境との相互作用を繰り返すことが難しい. 環境行動報酬次状態のデータから学習する → オフライン学習
DRL の種類
モデルあり DRL
モデルあり DRL は,遷移モデルや報酬モデルを知っている or 学習によって得る.つまり,ダイナミクスモデルを学習して,再現する.
学習したモデルをもとにポリシーを学習する.(MB-MPO, ME-TRPO) 既知のモデルに基づいて計画を立て,ポリシーのみ学習する(動的計画法,AlphaZero)
これらは環境を実際に遷移させなくてもモデルを学習することができる.
モデルなし DRL
- 価値ベース
- 状態ー行動の価値関数$Q(s, a)$を学習する.(Q 学習)
- 価値関数を用いてポリシーを学習する.
- 方策ベース
- 方策を直接学習し,そこから行動を選択する.
- 連続行動空間や確率的ポリシーにも対応,分散が大きい問題がある.
- 報酬が大きくブレるような設定において,ポリシーの学習が不安定になる.
- アクタークリティック
- 方策の「アクター」と価値関数の「クリティック」を学習する.(PPO,SAC,TD3)
Q 学習
Q 学習は,価値関数を用いてポリシーを学習する.
\[Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha (r_{t+1} + \gamma \max_{a_{t+1}} Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t))\]ここで,$\alpha$は学習率,$\gamma$は割引率である.
最大の特徴は,将来の報酬が最大だと仮定している点.
オンポリシーとオフポリシー
オンポリシー(on-policy):訓練データ生成に用いた方策(行動方策)と,学習対象の方策(ターゲット方策)が同じ.安定性が高いがサンプル効率が低い.
オフポリシー(off-policy):行動方策とターゲット方策が異なる.デモデータ活用やサンプルの再利用が可能だが,安定性や収束性に課題がある.
実際に環境を動かしながらやるか?という違いがある
計算量の推移
より複雑な訓練プロセスでは時間やリソースが多く必要となる.
DQN を Atari2600 で訓練するには 38 日分の体験データ(5000 フレーム)が必要. 学習も時間を要し,ハイパーパラメータの調整も困難.

atari 2600
ファミコンみたいなもの.中にいわゆるアーケードゲームが入っている 👾
DRL の訓練を加速させるために並列計算および分散計算を利用することが直感的な解決策となる. しかし発展は複雑で急速である. 従ってこの論文でまとめる.
分散訓練
基本的には AI 友達なので,深層学習の分散の考えが深層強化学習にも適用できる.
データ並列
訓練データを複数のワーカに分割,各ワーカが学習したパラメータを同期する. ワーカがそれぞれ学習を行い,パラメータは All-Reduce で共有して平均を取る.
flowchart LR
subgraph Worker1
A1(モデル)
B1(データバッチ 1 を処理)
end
subgraph Worker2
A2(モデル)
B2(データバッチ 2 を処理)
end
subgraph Worker3
A3(モデル)
B3(データバッチ 3 を処理)
end
B1 -->|勾配送信| C(勾配集約して平均)
B2 -->|勾配送信| C
B3 -->|勾配送信| C
C --> D(モデル更新)
モデル並列
モデルを分割し,各部分を異なるワーカで学習する.計算依存性が高いため並列化が難しい パーツごとにデータを受け渡して順次計算していく.
flowchart LR
subgraph Machine1
A(モデルの前半部分)
end
subgraph Machine2
B(モデルの中盤部分)
end
subgraph Machine3
C(モデルの後半部分)
end
Input(Data入力) --> A --> B --> C --> Output(結果出力)
パイプライン並列
モデルを複数のステージに分けて順次学習する.
flowchart LR
subgraph Machine1
A1(モデルの前半部分)
end
subgraph Machine2
B1(モデルの中盤部分)
end
subgraph Machine3
C1(モデルの後半部分)
end
Input1(データ1) --> A1 --> B1 --> C1 --> Output1(結果1)
Input2(データ2) --> A1 --> B1 --> C1 --> Output2(結果2)
Input3(データ3) --> A1 --> B1 --> C1 --> Output3(結果3)
併せ技も提案されている.
DRL の分散訓練に DL の分散技術をそのまま使うのはちょっと問題がある
- Agent,Env,パラメータサーバなどが強調するため,アーキテクチャ設計と分配が難しい.
- デバイス間データ転送が多く,スループットが下がりやすい
- 並列環境では処理速度が異なるので古い勾配で学習してしまうと収束性が下がる
DRL の分散訓練のアーキテクチャ(パーツ)
- Actor:環境と相互作用し,方策に従って行動し,観測や報酬などの情報を取得し,経験データを生成する役割.
- Learner:経験データを収集またはサンプリングし,モデル更新のための勾配を計算する.GPU のような高速ハードウェアがしばしば用いられる.
- パラメータサーバ(Parameter Server):Actor や Learner のためにニューラルネットワークの最新パラメータを保持する役割.一部の方式では,Learner がこの役割を兼ねる場合もある(例:APE-X や R2D2).
- リプレイメモリ(Replay memory):Actor が生成した経験データを保存する場所.これはオフポリシー強化学習において使用される(例:Gorila,Ape-X,R2D2).
集中型アーキテクチャ
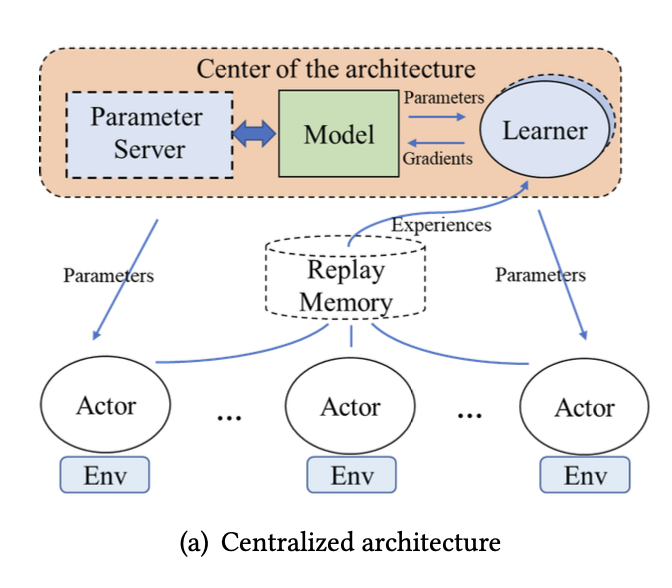
学習用のニューラルネットワークのグローバルモデルを 1 つの中心ノードが保持する.Learner は Actor からの経験をもとに勾配を計算してこのモデルを最適化する.Learner および Actor は,定期的にこのグローバルモデルと同期する.中心ノードはパラメータサーバか Learner が担当する.
GOOD
- 設計が容易
- 同期が容易
BAD
-
中心ノードへの負荷が大きい
- Gorila
- 多数の Actor と Learner で訓練を並列化
- Ape-X
- 経験の優先度付きサンプリングにより効率化
- パラメータ更新は GPU 上の単一 Learner が担当.バッチ処理.
- R2D2
- LSTM による部分観測環境への対応
- A3C
- Actor と Learner を 1 つのスレッドにまとめる.
分散型アーキテクチャ
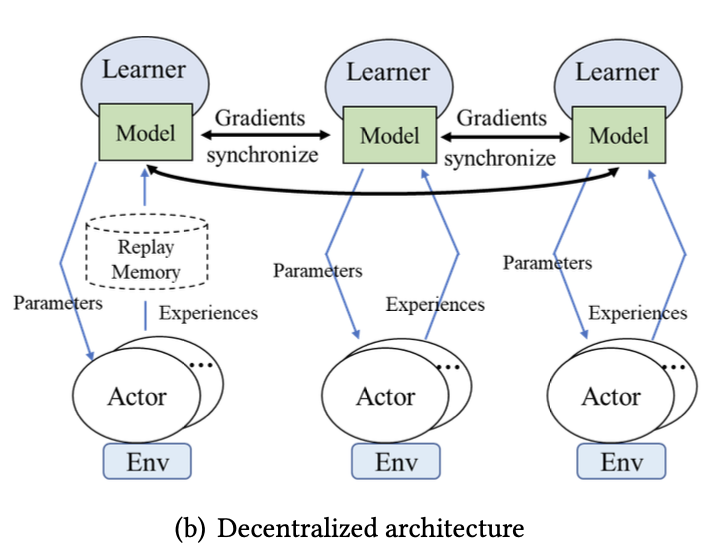
中心ノードを持たず,複数の Learner がそれぞれ自分の Actor からの経験に基づいて勾配を計算し,お互いに勾配を共有することでモデルを更新する.「All-reduce」と呼ばれる通信方式を用い,パラレルワーカー間で完全に接続されたトポロジーが必要となる.
概要
- IMPALA
- CPU で環境との相互作用を行う Actor と,GPU で学習を行う Learner で構成.
- Learner 間で勾配を同期し,Actor は Learner から最新パラメータを受け取る.
- rlpyt(Stooke ら):
- 複数 GPU を用いた並列化
- GPU がデータのサンプリングと推論を実行,ALL-reduce で共有
- DD-PPO
- 複数マシンへの拡張
GOOD
- 中心ノードがないためスケーラブル
BAD
- 勾配共有に時間がかかり通信オーバーヘッドが大きい
シミュレーションの並列性
環境との相互作用でデータを集めるという点が DRL の大きな特徴である. 現実を模倣したシミュレーションにより,効率的な訓練が行われることが多い.
CPU クラスタを用いた並列(ナイーブな手法)
CPU クラスタを用いて分散実行する.
- システム全体の CPU コア数にスケーラビリティが依存する
- ノード間通信・同期・リソース割り当てにオーバーヘッドがある
- CPU・GPU 間でのデータ転送がオーバーヘッドとなる
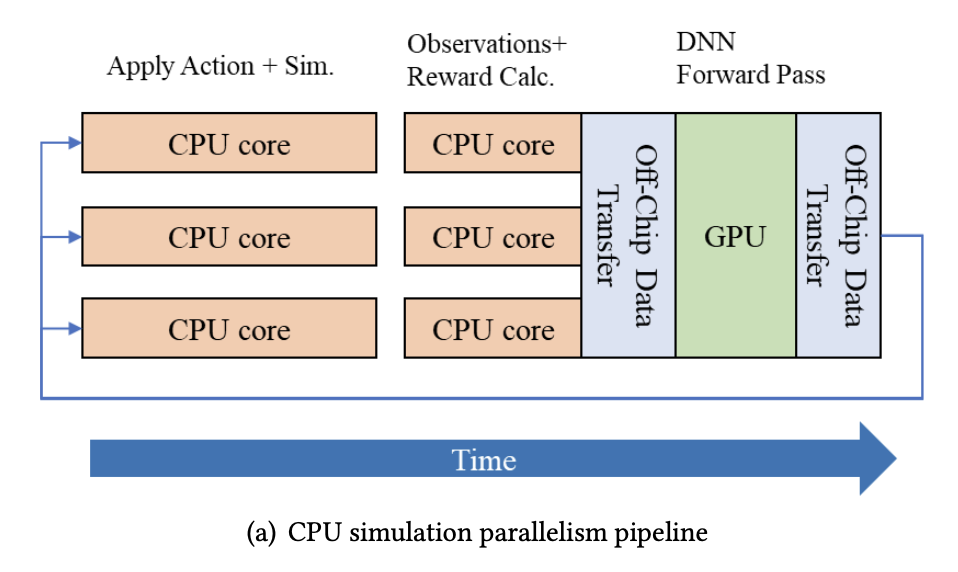
GPU・TPU によるバッチシミュレーション
GPU によるシミュレーションの高速化が進む
一方で,CPU-GPU 間のデータ転送は避けられない.
ゼロコピーシミュレーション
- CuLE(CUDA Learning Environment)
- Atari を GPU で直接動かす.
- Issac Gym
- ロボット制御のためのシミュレーションプラットフォーム.
- TensorAPI の活用により GPU のみでの学習を実現
- Brax
- TPU 上でのシミュレーション
推論やバックプロパゲーションの並列化
クラスタコンピューティング
はじめは Mapreduce が主流であった.しかしシミュレーションの大規模化に伴い不十分となったところから,DistBelief が始まった. しかしその手法は DL を対象としており,DRL とは目的が違う. そこで,Gorila や Ape-X などの手法が提案された.
単一マシン並列処理
スパコンのようなクラスタには手が届きにくい一方で,ワークステーションは手に届きやすい. そのような単一マシンでの並列化は,マルチプロセッシングとマルチスレッディングである. 代表的なものに A3C がある. A3C では多数の Actor,Learner が並列に起動される.
専用ハードウェアアーキテクチャ
推論や訓練での行列計算には GPU や FPGA,TPU が必要である.
分散における同期
分散確率的勾配降下法(Distributed Stochastic Gradient Descent: DSGD)**を用いて複数のワーカーが協力してモデルを訓練する
flowchart LR
subgraph Worker1
A1(ミニバッチ 1) --> B1(勾配計算)
end
subgraph Worker2
A2(ミニバッチ 2) --> B2(勾配計算)
end
subgraph Worker3
A3(ミニバッチ 3) --> B3(勾配計算)
end
B1 --> C(勾配集約(All-reduce))
B2 --> C
B3 --> C
C --> D(勾配平均して全員パラメータ更新)
有名な同期手段
- バルク同期並列(Bulk Synchronous Parallel: BSP)【129】
- 非同期並列(Asynchronous Parallel: ASP)【130】
- 遅延同期並列(Stale Synchronous Parallel: SSP)【131】
非同期オフポリシー訓練
- パラメータサーバがグローバルモデルを保持.
- 各 Actor は環境との相互作用で生成した訓練データを Replay Memory に送信し,最新のパラメータを非同期にサーバから取得する.
- Learner は Replay Memory 内のデータを使ってグローバルモデルを更新する.
同期オンポリシー訓練
Discussion
進化型深層強化学習
- 初期化:個体の集団をランダムに生成する.
- 評価:各個体の性能を環境内で評価し,スコアを与える(=フィットネス).
- 選択:優れた個体を選び出し,次の世代に残す.
- 変異/交叉:選ばれた個体に小さな変更(突然変異)や組み合わせ(交叉)を加えて,新たな個体を生成する.
- 更新:新たな集団に置き換えて次世代へ進む
(1)OpenAI-ES(Evolution Strategy)
- OpenAI が提案した,スケーラブルなブラックボックス最適化手法.
- ノイズを加えた複数のポリシーを一斉に評価し,その結果に基づいてパラメータを更新する.
- 数千の CPU コアで並列化可能であり,高次元でも安定した訓練が可能.
GOOD
- 勾配に依存しないため,不連続な環境でも適用可能
- 探索の多様性を維持できるため,局所解に陥りにくい
- 高並列化性により,大規模クラスタや GPU/TPU 環境で高速訓練が可能
BAD
- サンプル効率が低く,訓練に大量の環境ステップが必要
- 進化アルゴリズム自体がハイパーパラメータに敏感である
- 大規模な探索を行うためには,計算資源が大量に必要となる場合がある