DeepSeekR1
かの有名な DeepSeekR1 の論文を読みました.
背景
これまでの LLM 研究は,モデル性能の向上が大量の教師ありデータに大きく依存してきた.
本研究では以下の 2 点を示す.
- RL 的アプローチにより,教師ありファインチューニング(SFT)を初期段階として使用しなくても,大規模な強化学習(RL)を通じて推論能力を大幅に向上させることができること
- 少量のコールドスタートデータを含めることで,性能をさらに向上させることができること
OpenAI の o1 倒す!
本研究では GRPO(Shao et al., 2024)という RL フレームワークを使って推論性能を向上させる.
提案手法
DeepSeek-R1-Zero:ベースモデルに対する強化学習
教師ありファインチューニングなしで,ベースモデルに直接 RL を適用したもの.
Group Relative Policy Optimization(GRPO)
通常はポリシーモデルと同じサイズの「クリティックモデル」を使うが,それを省略し,グループスコアからベースラインを推定する.
概要
各質問 $q$ に対して,旧ポリシー $\pi_{old}$ から複数の出力 ${o_1, o_2, …, o_G}$ をサンプリングし,以下の目的関数を最大化するように新しいポリシー $\pi_\theta$ を最適化する:
\[J_{GRPO}(\theta)=E_{q\sim P(Q),\{o_i\}_{1}^{G}\sim\pi_{old}}[\frac{1}{G}\sum_{i=1}^{G}min(\frac{\pi_{old}(o_i|q)}{\pi_{\theta}(o_i|q)}A_i,clip(...))-\beta D_{KL}(\pi_{\theta}||\pi_{ref})]\]ここで,$A_i$ は次のように定義される:
$A_i = \frac{r_i - mean({r_j})}{std({r_j})}$
りんごは赤いですか?
π<{はい,赤いです. はい,緑です.いいえ,赤です...}>
報酬獲得
π←π’
報酬モデル
-
正解報酬(Accuracy rewards)
たとえば数学問題では,答えを「ボックスで囲む」など決まった形式で返すようにし,正誤判定を自動化する.LeetCode のようなコード問題では,テストケースでコンパイル確認する. -
形式報酬(Format rewards)
思考過程を <think> と </think> のタグで囲むことを義務づけ,形式の正しさに報酬を与える
注意: ニューラルネットによる報酬モデル(学習済みの報酬モデル)は使用しない.その理由は,報酬ハッキング(裏技みたいな学習)が発生しやすく,再学習にも計算資源がかかり,パイプラインが複雑になるからである.
報酬を紐解く
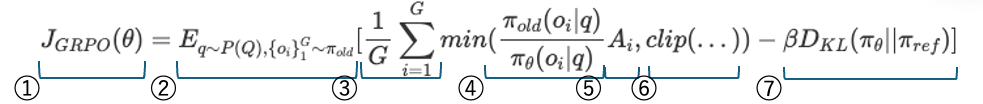
- 現在のパラメータに対するスコア
- 問題集合 $Q$ から $q$ をサンプリング,古いモデルから解答を $G$ 個サンプリング
- 各解答に対して平均を取る
- 今のモデルがその答えを出す確率と古いモデルがその答えを出す確率の比率
- $A_i = \frac{r_i - \text{mean}(r)}{\text{std}(r)}$:標準化された優位性.答えがどのぐらいグループの中で優れていたか.
- 報酬クリッピング(過大評価を防ぐ)
- 罰則項.前のモデルの出力傾向と大きく異なろうとすることを防ぐ.
トレーニングに使うプロンプト
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user
with the answer. The reasoning process and answer are enclosed within <think> </think> and
<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: prompt. Assistant:
アシスタントはまず頭の中で推論の過程を考え,その後ユーザーに答えを提供する。
推論の過程と答えはそれぞれ <think> </think> および <answer> </answer> タグで囲まれる。
すなわち,<think> ここに推論過程 </think>
<answer> ここに答え </answer> のように記述される。
結果
学習が進むにつれ,DeepSeek-R1-Zero の応答はどんどん長くなり,つまり「思考時間」が増加することがわかる.この時間の増加は外部からの指示ではなく,モデル自身の学習によって自然に現れたものである. アハ体験をするようになった.
自分の結果から学び直してまた賢くなるということ.
DeepSeek-R1
数千の長い思考過程(Chain-of-Thought: CoT)の例でファインチューニングされたチェックポイントから RL を適用したもの.
RL ベースの DeepSeek-R1-Zero とコールドスタートの併せ技
学習パイプラインの定義
Cold Start
RL はゼロから始めるのではなく,少量の長い思考過程(Chain-of-Thought: CoT)の例でファインチューニングされたチェックポイントから始める.
具体的には,長い CoT を含む few-shot プロンプトによる出力の生成,反省や検証の生成,データの後処理.
ワークしたの?
- 出力の末尾に要約を含めるフォーマットにより可読性が向上した.
- 人間の設計に基づくパターンを取り入れうことで性能が向上した.
Few-shot の活用.
RL (Reasoning-oriented Reinforcement Learning)
コーディング,数学科学など明確な正解が存在するタスクを重点的に学習
言語の混在を防ぐため,言語一貫性報酬を導入した.
Rejection Sampling and Supervised Fine-Tuning
RL 収束後,SFT(Supervised Fine-Tuning)のデータ収集を行う. Rejection Sampling;複数の出力を生成し解答だけ選ぶ.約 600,000 件
Reinforcement Learning for all Scenarios
有用性,無害性を高めるため 2 段階 RL を行う.
倫理観チェックはここで行われている.
蒸留
DeepSeek-R1 から小さな密モデルに推論能力を引き継ぐ(distill する)手法.
評価
ベンチマークでの正解率
| ベンチマーク | 説明 |
|---|---|
| AIME 2024 | 難度の高い数学ベンチマーク(中高生向けのオリンピック風) |
| MATH | 証明形式の数式問題集 |
| GSM8K | 小学生向けのステップ付き算数問題 |
| LeetCode-Easy / Medium / Hard | コーディング問題(段階別) |
| CMATH | 中国の高校数学 |
| LogiQA / OpenBookQA / StrategyQA / ARC-C | 論理・科学・推論タスク |
| MathBench | 思考力を求める一貫した測定セット |
DeepSeek-R1 は,OpenAI o1-1217 と同等かそれ以上の性能を示す
一般能力・有用性・無害性
QA,翻訳,計算,常識などで測定 FLASK(LLM 向け有害性&有用性の評価フレームワーク)によって,回答の親切さ・安全性を測定
有用性って何?
その回答が人間にとって役に立つか.また,回答の優しさも評価に含まれる.
例:「スマートフォンのバッテリーを長持ちさせたいです.どうすればいいですか?」
- 有用:「明るさを下げる,バックグラウンドアプリを止める,充電のしすぎを避けるなどが効果的です.また,バッテリー消費が激しいアプリを設定から確認すると良いです.」
- 有用でない:「スマートフォンを使わないようにしましょう.」
考察
Discussion
- Aha moment
- AI が自分で考えるようになった.ひらめき(アハ体験)や反省を通した思考をするようになった.正確には,そのような思考過程を出力できるようになった.
- モデルの思考過程を理解するためには,CoT が必要.考える力だけでなく,理論をつなげる力も進化している.
- LLM as Thinkers
- もはや考える生き物のようだ
関連研究
| アプローチ | 研究者 | 年 |
|---|---|---|
| プロセスベースの報酬モデル | Lightman et al. Uesato et al. Wang et al. | 2023 |
| 強化学習 | Kumar et al. | 2024 |
| モンテカルロ木探索やビームサーチ | Feng et al. | 2024 |
| グループ相対方策最適化(GRPO) | Shao et al.(本論文の採用手法) | 2024 |